|
Ph.D. Student, Computer Science, Stanford University Email: shgwu [AT] cs [DOT] stanford [DOT] edu |

|
|
I am a second-year CS PhD student at Stanford, advised by Serena Yeung-Levy. Previously, I completed my Master's at Peking University, advised by Qi Su, and worked with Qwen Team on open-source LLM research.
I study how foundation models and agents self-improve and continually learn from experience — refining their skills, memory, and tools over time, and adapting to new tasks well beyond their initial training. I am especially interested in models grounded in the physical world: sensing and acting in embodied environments, and learning from how the world reacts to their actions.
|
|
|
(see also Google Scholar)
|

|
ArXiv, 2026
TL;DR: We make memory management a trainable skill for LLM agents. AutoMem automates the learning of this skill end-to-end: automatically optimizing the agent scaffold (memory structure) and training a dedicated memory specialist from the agent's own traces (memory proficiency). This automated learning alone brings an open-weight Qwen2.5-32B to frontier-level performance on long-horizon tasks.
|
|
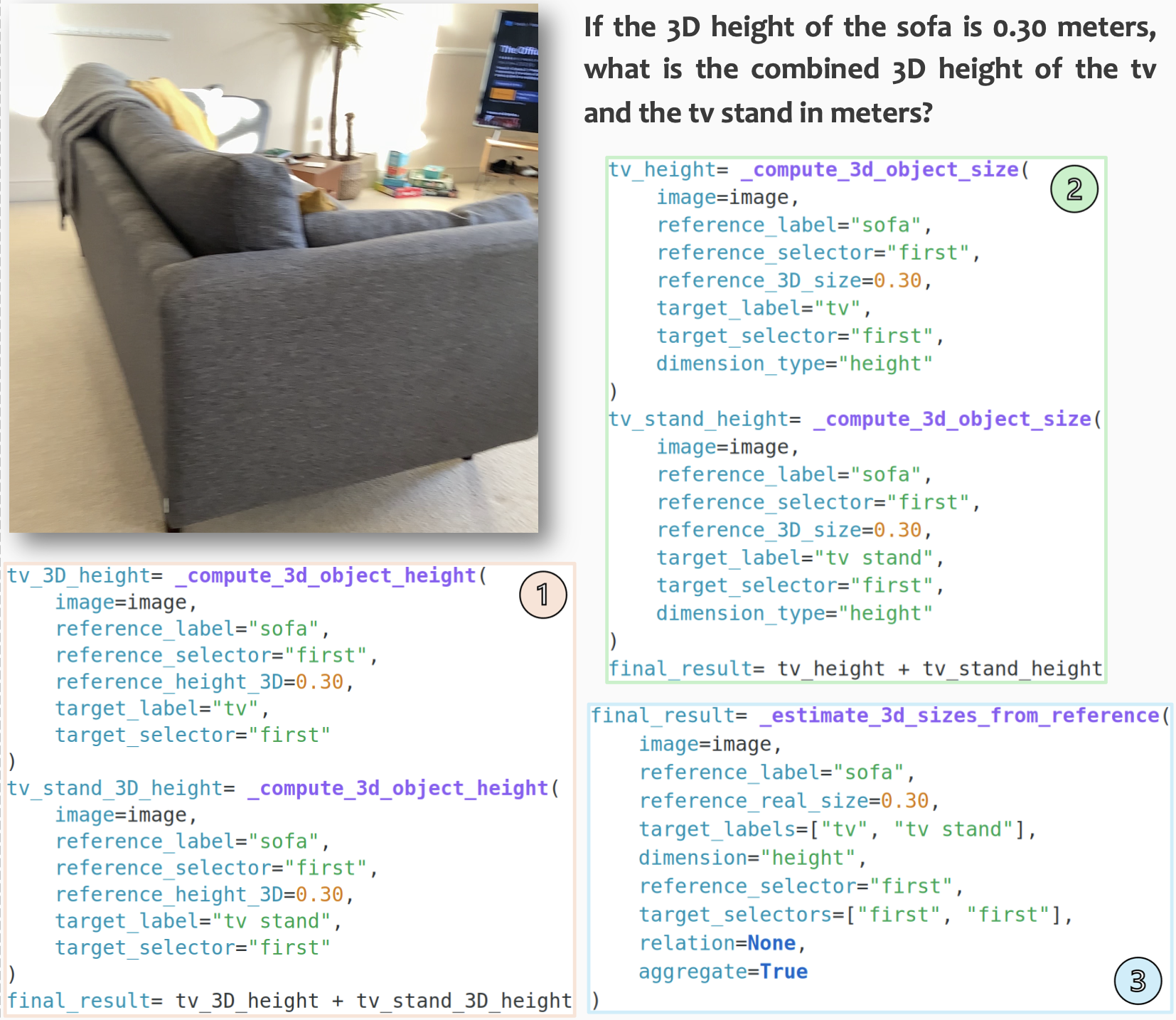
Transductive Visual Programming (TVP): Evolving Tool Libraries from Experience for Spatial Reasoning
ICLR, 2026
TL;DR: TVP is a new visual programming framework that builds reusable tools from its own problem-solving experience via two interconnected libraries: an Example Library that accumulates program solutions as experience, and a Tool Library that maintains functions abstracted from these programs. The dual-libraries enable the circular program-tool-program cycle: solving problems generates experience, experience guides tool creation, and newly created tools improve future problem-solving.
|
|
"An international restaurant with vibrant decor."
|
3DV, 2026
TL;DR: 3D-Generalist is a generative graphics framework for creating 3D environments. Key modules include: 1. a diffusion-based panoramic generator that renders environment structures; 2. a VLA trained via self-improving loop for code generation to refine the environments; and 3. another VLA for placing diverse unlabeled 3D assets. 3D-Generalist provides a controllable pipeline to scale up synthetic 3D environment data for embodied AI.
|
|
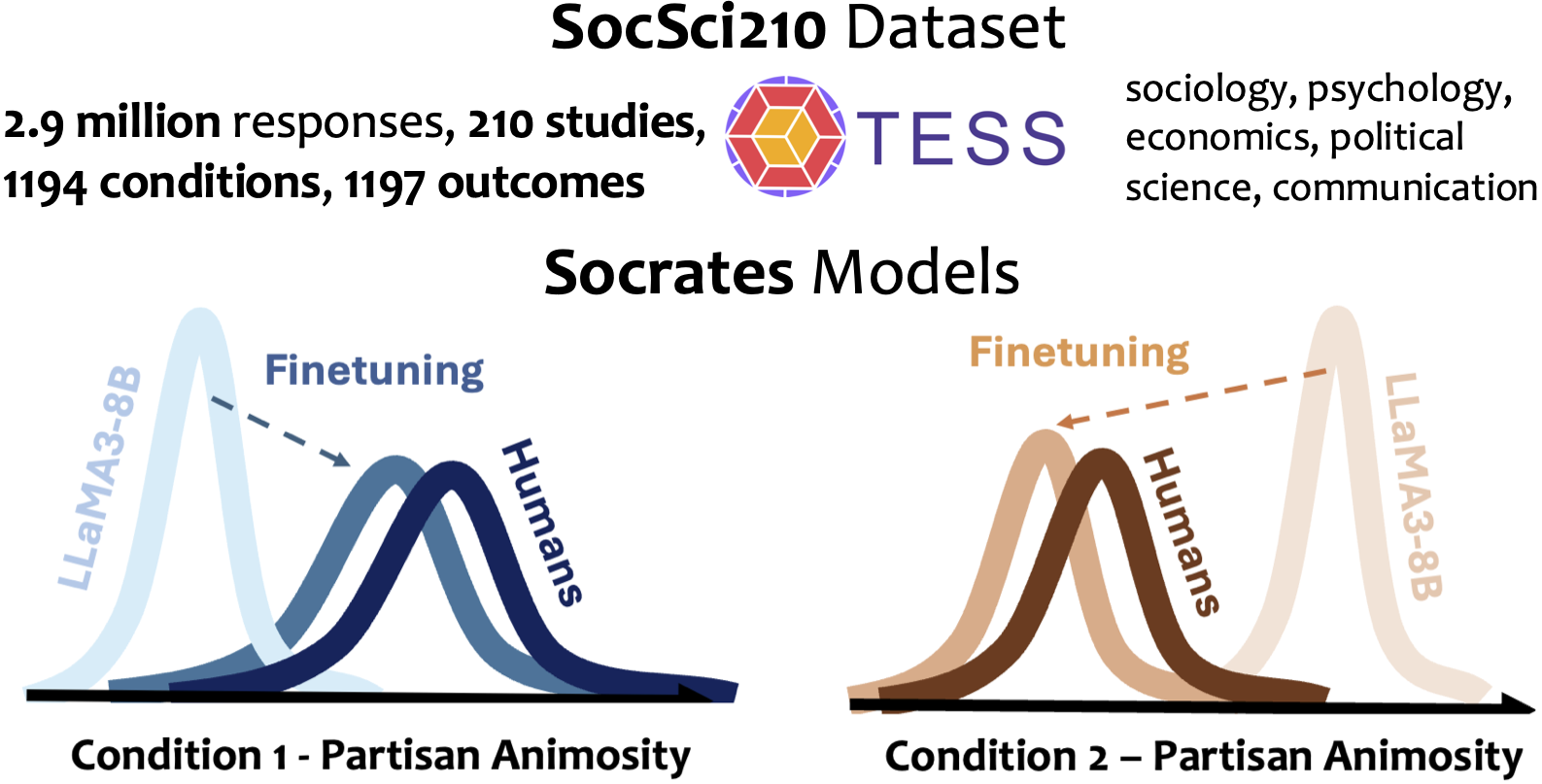
EMNLP-Main, 2025
TL;DR: We release SocSci210, a dataset of 2.9 million responses from 400,491 participants across 210 social science experiments. Through finetuning, our Socrates models achieve substantially better alignment with human response distributions under varying experimental conditions. We show that finetuning on just a subset of conditions within a study enables robust generalization to unseen conditions, demonstrating the potential for accurate experimental hypothesis screening with limited sample data.
|
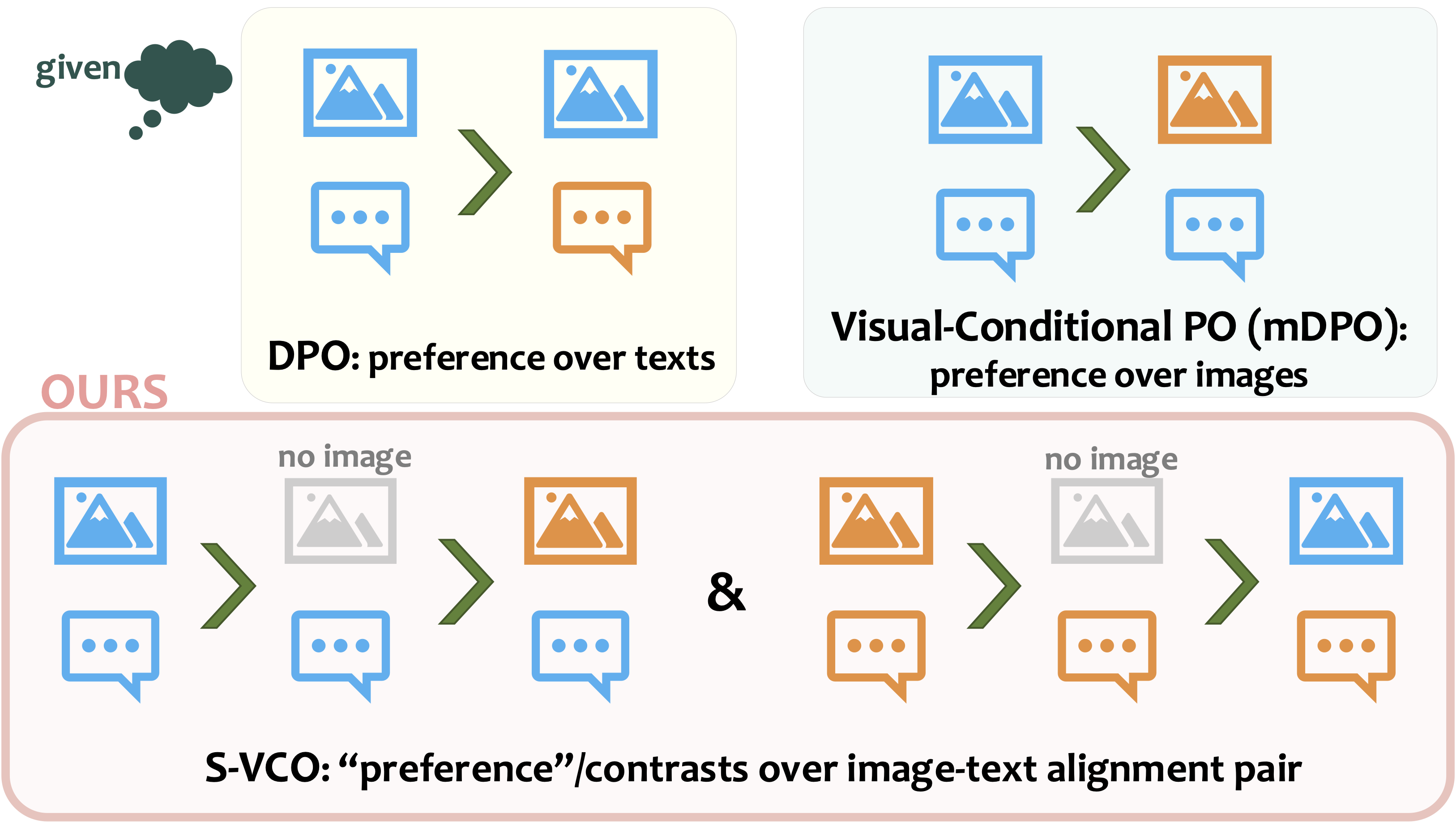
|
ACL-Main, 2025
TL;DR: S-VCO is a novel finetuning method that enhances visual-centric capabilties of VLMs while preserving general performance. Key design is a symmetrical visual contrastive objective that optimizes over visual details while avoiding one-sided "preference" formulation. Across various VLM benchmark domains, S-VCO demonstrates most significant and consistent improvements, with especially strong gains on visually demanding tasks.
|
|
EMNLP-Main, 2024
TL;DR: We proposed novel paradigms for assessing and enhancing social-pragmatic abilities in L(V)LMs. Key results include: 1. open-ended evaluation better reveals LLMs' pragmatic generation as opposed to multiple-choice setup; 2. preferential tuning effectively invokes pragmatic reasoning without compromising generic abilities; 3. improvement of the speaker model's multimodal theory of mind in image referential games.
|
|
ArXiv, 2023
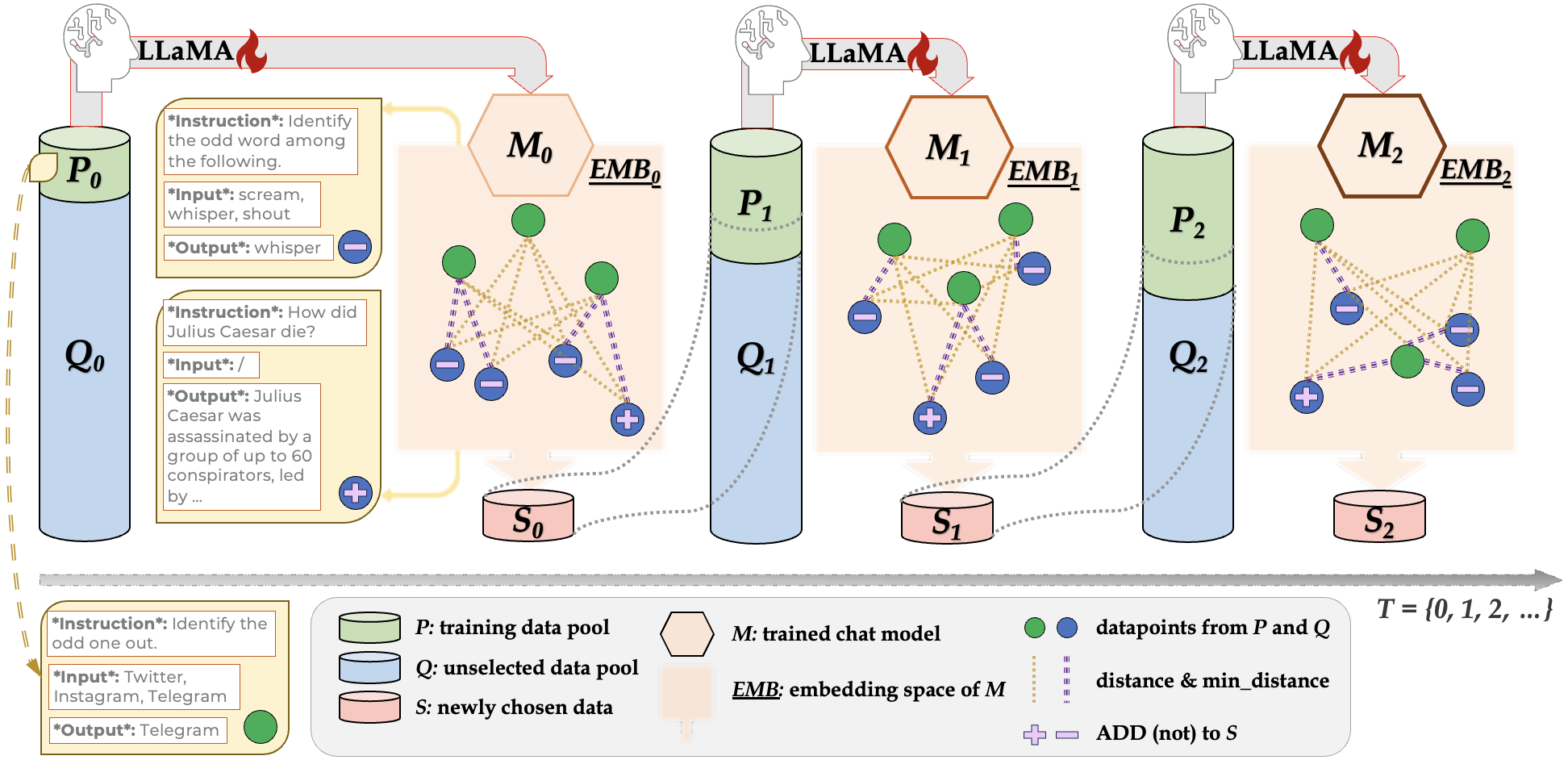
TL;DR: DiverseEvol is an efficient instruction-tuning method that allows the model itself to iteratively sample training subsets to improve its own performance, with a key selection principle of maintaining high diversity in the chosen subsets. Across three datasets and benchmarks, our models, trained on less than 4% of the original dataset, match or improve performance compared with finetuning on full data.
|
|
ArXiv, 2023
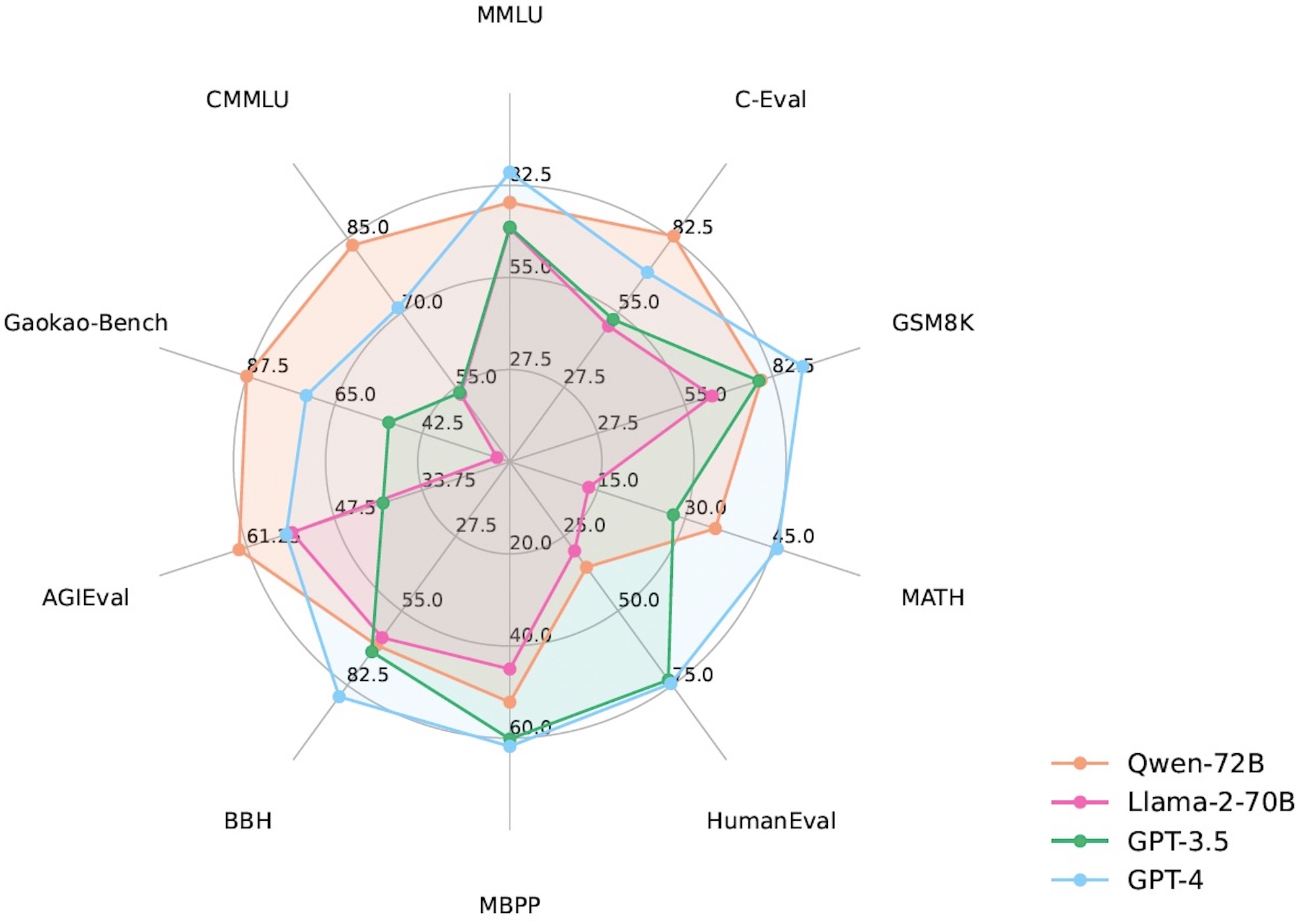
TL;DR: We release Qwen, a family of highly-capabale foundation LLMs and Chat-Models. QwenLMs achieve superior performance than baselines (e.g., LLaMA2) of similar sizes on a wide range of benchmarks that measure natural language understanding, reasoning, problem solving, etc. Qwen-72B also outperforms GPT-3.5 on 70% of all tasks.
|
Website template from YueYANG1996.github.io. |